企业出口强度与产品质量的相互影响 ——质量促进效应还是出口学习效应
来源:《财贸研究》
2020-02-26 10:24:02
经过30多年的持续快速发展,中国在全球贸易中已经占据了举足轻重的地位。然而,中国虽已是贸易大国但还没有成为贸易强国,在全球价值链中仍处于较低的位置,其出口产品结构、产品质量和附加值与贸易强国还有较大差距。提高产品质量和附加值,实现在全球价值链上的攀升,从“大进大出”转向“优进优出”,是实现下一阶段中国对外贸易跨越发展的必经之路。作为对外贸易的微观主体,企业行为决策会影响产品质量,而产品质量又是影响企业发展壮大并进入国外市场的重要因素。
近年来,以Melitz(2003)为代表的异质性企业贸易理论逐渐兴起,该理论在新贸易理论的基础上引入企业异质性,从企业层面探讨贸易的动因和结果。但Melitz(2003)理论有两点假设亟待扩展:一是仅关注企业生产率异质性,而不考虑其他方面的差异性特征;二是将消费者偏好用CES(固定替代弹性)效用函数表示,即仅关注消费者对产品多样化的需求,而不关注同类产品的质量差异性。虽然是出于模型简化的需要,但与现实明显不符,导致结论与现实企业贸易行为出现矛盾。为解决这一问题,学者们提出了不同的拓展方法,而引入产品质量异质性是重要思路之一。另外,Melitz(2003)模型出现以后,许多研究文献对其中的关键推论,即出产率与企业出口之间的正相关关系进行了多方位的实证检验,其中最重要的是对两种假说进行检验:一是自我选择效应,即生产率较高的企业才会出口;二是出口学习效应,即出口会使企业生产率得以提高。那么,在将产品质量异质性纳入企业异质性之后,在产品质量与企业出口决策之间是否也存在像生产率与企业出口之间那样的相互关系;进一步地,在产品质量与企业的出口强度决策之间是否也存在相互的促进作用。目前鲜有文献对此问题进行探讨,本文将对此进行初步检验。
一、计量模型
为探讨企业不同出口强度对产品质量的影响,以及在不同产品质量水平下出口强度的变化,要考察企业出口产品质量与出口强度之间的关系,分别建立如下动态面板数据模型:

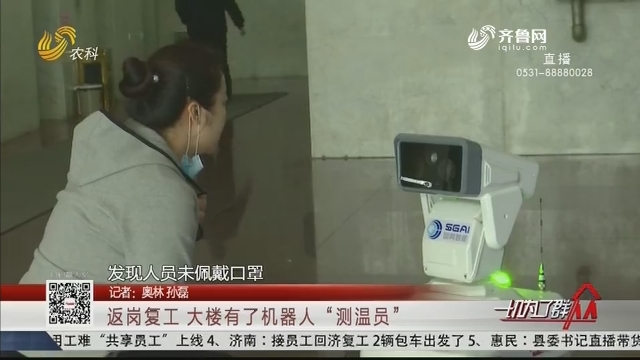
二、变量说明

表1 变量定义明细表
三、数据来源与处理
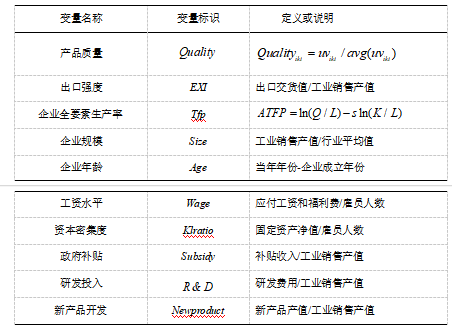
本文数据来自《中国工业企业数据库》和《中国海关进出口数据库》的匹配。《中国工业企业数据库》中企业层面生产数据是度量企业全要素生产率等控制变量的数据来源,而《中国海关进出口数据库》中产品层面的贸易数据则被用于度量企业的出口产品质量。在进行两个数据库匹配之前要对两个数据库分别进行处理。对《中国工业企业数据库》的处理方法遵循如下原则:考察时间段为2001-2006年期间持续经营企业;行业代码开头两位为13-42的制造业企业。具体处理数据过程中参照谢千里等(2008)的做法对数据进行以下筛选:删除本文涉及变量中存在缺漏值的样本;删除雇员人数小于10的企业样本;删除工业增加值、固定资产净值年平均余额、本年应付工资和应付福利费、补贴收入、研发费用、新产品产值小于0的企业样本;删除1900年之前成立的企业样本,最后得到60540家企业样本5年的数据。对《中国海关进出口数据库》的处理,先按照前文所述的方法将相同企业合并,求其多种出口产品的平均质量。然后删除各相关变量存在缺漏值的样本,得到34007家企业样本5年的数据。
在分别对两种数据进行处理之后,要对两个数据库的企业样本进行匹配。借鉴余淼杰(2011)等学者的方法,首先利用两数据库中的企业名称进行匹配,然后用两数据库中企业的邮政编码和电话号码后7位进行匹配,最后匹配出8210家企业样本5年的数据共41050个样本观察值。从匹配结果来看,匹配的8210家企业占海关进出口数据库中有效持续经营企业数的24%,占工业企业数据库中有效持续经营出口企业数的29%,说明匹配结果可以接受。需要说明的是,海关数据库中包含大量的专业贸易公司样本,会在一定程度上干扰实证检验结果,而在同工业企业数据库匹配之后绝大部分都被筛除了,这样有助于提高实证检验的准确性。
表2 数据样本基本情况摘要
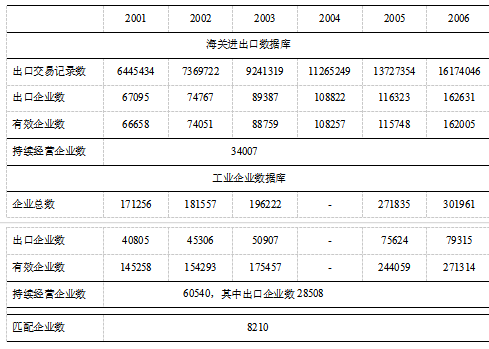
表3 变量的描述性统计特征
(一)内生性分析及处理四、实证结果分析
前文讨论过的,产品质量可能会对企业的出口强度产生影响,即存在“质量促进效应”,反过来企业的出口决策也有可能影响产品质量的升级,即存在“出口学习效应”。因此,模型很可能存在反向因果关系导致的内生性问题。严重的内生性问题会导致混合OLS方法、固定效应方法或随机效应方法的估计结果是有偏的和非一致的,可选的解决办法是工具变量法,但是工具变量的选择及其效果具有很大的不确定性。
同时,由于计量模型中包含因变量的滞后项,样本数据成为动态面板数据,这种情况下即使组内估计量(FE)也是不一致的,有效的估计方法是广义矩估计(GMM)。其中,系统GMM将内生解释变量的差分滞后项作为水平方程中内生解释变量的工具变量,以解决弱工具变量问题,采用系统GMM方法对动态面板数据模型进行估计。为了保证系统GMM估计的有效性,本文采用Arellano-Bond AR(2)和Sargan检验来判断工具变量和估计结果的有效性。其中Arellano-Bond AR(2)用于判断差分方程的残差是否存在二阶序列相关,其原假设不存在序列相关,估计结果是有效的;Sargan检验主要用于判断是否存在过度识别约束,其原假设为模型中工具变量的选取是有效的。

想爆料?请登录《阳光连线》( http://minsheng.iqilu.com/)、拨打新闻热线0531-66661234或96678,或登录齐鲁网官方微博(@齐鲁网)提供新闻线索。齐鲁网广告热线0531-81695052,诚邀合作伙伴。
庞德《诗章》中的纳西王国
- 在硕果累累的“庞德与中国”研究中,庞德对丽江纳西族文明的书写研究显得相对薄弱。事实上,从《诗章》第101章到第110章,纳西风景、神话、...[详细]
- 《外国文学研究》 2020-01-14
美丽中国建设的中外思想资源
- 美丽中国建设的理念,并非悬空思索而来,而是在充分汲取中外智慧基础上,结合中国当前国情,对于中国未来发展之路做出的科学而美好的构想。[详细]
- 齐鲁网 2019-11-13
人工智能与数学教育深度融合:问题解决认知模拟
- 当前,大数据、云计算、移动互联网等技术的快速兴起及广泛应用,为推动教育创新提供了无限广阔的空间。[详细]
- 齐鲁网 2019-09-20
科学把握经济高质量发展的内涵、特点和路径
- 我们要全面理解高质量发展的理论内涵,把握高质量发展渐进性、系统性的重要特征,推动经济发展质量变革、效率变革、动力变革。[详细]
- 经济日报 2019-09-18
新中国哲学社会科学的成就与经验
- 中华人民共和国的诞生,开辟了中华民族历史发展的新纪元,也开启了中国哲学社会科学发展的新纪元。70年来,在党的领导下,哲学社会科学与时...[详细]
- 经济日报 2019-09-18
中国发展蕴含的工业化规律
- 注重发挥比较优势,不断优化经济结构;正确处理工业化、城镇化、农业现代化、技术进步之间的关系,实现新型工业化、信息化、城镇化、农业现...[详细]
- 人民日报 2019-08-29
马克思恩格斯经典文本批判错误社会思潮的逻辑进路
- 立足马克思恩格斯的经典文本,梳理其分析批判错误社会思潮的逻辑进路,对于当代进一步丰富、发展马克思主义具有重要的理论意义和现实价值。[详细]
- 光明日报 2019-08-26
充分发挥口述史学的跨学科应用价值
- 口述史学的跨学科特征与趋势涉及资料、方法、工具、视角、概念、理论等在不同学科之间的相互整合、渗透、交叉与借用。[详细]
- 人民日报 2019-08-26
讲出思想政治理论课应有的精彩
- 思政课能不能真正发挥好立德树人的关键性、不可替代性作用,归根到底还要看思政课的教学质量;思政课能否为学生真心喜爱、终身受益,归根到...[详细]
- 《求是》 2019-08-16

【100秒漫谈新思想】之不忘初心 牢记使命
- “不忘初心、牢记使命”,就是要守初心、担使命,找差距、抓落实,要理论学习有收获、思想政治受洗礼、干事创业敢担当、为民服务解难题、清...[详细]
- 齐鲁网 2019-08-16
推动新时代思政课守正创新
- 进一步强化马克思主义理论学科对思政课的学理支撑,推动当代中国马克思主义、21世纪马克思主义研究,以学科建设反哺教育教学,以理论创新促...[详细]
- 人民日报 2019-08-06
把爱国奉献作为知识分子的精神标识
- 进入新时代,以黄大年、南仁东为代表的广大知识分子把爱国之情、报国之志融入祖国改革发展的伟大事业之中、融入人民创造历史的伟大奋斗之中...[详细]
- 光明日报 2019-07-02
牢牢把握“四个迫切需要” 深刻认识开展主题教育的重大意义
- 习近平同志指出,“开展这次主题教育,是用新时代中国特色社会主义思想武装全党的迫切需要,是推进新时代党的建设的迫切需要,是保持党同人...[详细]
- 人民日报 2019-07-02